
常见大模型语言能力测评

AI-摘要
Chat GPT
AI初始化中...
介绍自己 🙈
生成本文简介 👋
推荐相关文章 📖
前往主页 🏠
前往爱发电购买
常见大模型语言能力测评
Jerry Zhou测评内容
本次测试的模型包括 gpt-4-turbo, claude-3-opus-20240229, gpt-4o, qwen-max, qwen-plus, glm-4, deepseek 和 百度文库文档助手
本次测试使用的 Prompt 为 请以云为话题,帮我写一篇内容丰富、立意深刻、语言优美的议论文,评价方法较为主观,欢迎在评论区发表不同意见
测试结果
- GPT-4-Turbo:个人认为GPT-4-Turbo在中文文学类文本的撰写上非常糟糕,语言不够优美,立意一般也不是很恰当,并且用通篇关键词强行串联起混乱的逻辑,很多时候还夹杂很多的翻译腔。
gpt-4-turbo

- Claude-3-Opus:Claude-3-Opus中,通篇关键词的问题依然存在,写作对象也不是很明确,但是Opus的立意比较深刻,文采也还算过关,还会使用多种修辞手法。
claude-3-opus-20240229
- GPT-4o:新升级的GPT-4o在中文表现方面让人比较惊喜,文采和文章深度都得到了很大的提升,这一次GPT-4o终于会引用正确的名言警句了只是说话偶尔还是会有一股翻译腔不过已经不太严重。
gpt-4o
- 通义千问 2.5:通义千问系列的文采一直都很好,但是文章中喜欢出现转折并且比较生硬,文风也很难保持一致。可能是数据不太干净,通义千问很喜欢输出“行至水穷处,坐看云起时”这一句名句。同时,通义千问编造名句的情况也不少,感觉称不上“最强中文大模型”。
qwen-max
- 通义千问 1.5:上面说的问题基本上是通义千问模型的通性,只是1.5的模型会更加严重,逻辑不清晰,很多时候输出的东西看起来很有文采,但其实就是一派胡言,前言不搭后语。之前对通义千问印象很好
(因为它帮我写的作文拿过一等奖),但是这次再看似乎没有了之前的惊艳。qwen-plus
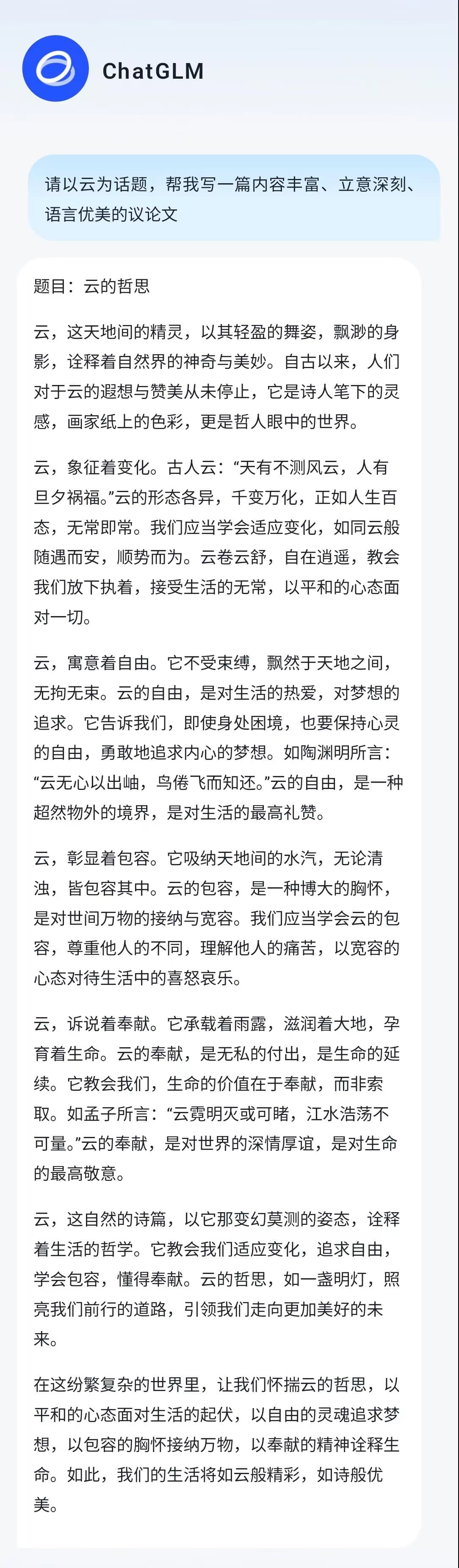
- ChatGLM-4:最近GLM-4的中文能力感觉提升不小,不过在写文章的时候比较喜欢铺陈罗列,逻辑不是很清晰,经常会出现前言不搭后语的情况,也存在乱用名言名句的情况。
glm-4
- 百度文库文档助手:百度文库文档助手在文学类文本的表现上一直优于文心一言和其他一众大模型,写出来的文章一直很有文采。只是在涉及专业的领域中经常会胡编乱造,并且有2000字的字数限制。
百度文库文档助手
- Deepseek:Deepseek的表现中规中矩,文采和逻辑都还算过得去,不过立意偏差,只是乱用名句的情况非常严重,并且可能测试数据来源不太干净,在相同任务下,很容易输出和其他模型一样的名句。
deepseek







评价与排序
个人主观认为在这个任务中,各模型表现排序如下:
百度文库文档助手>gpt-4o>qwen-max>glm-4>deepseek>qwen-plus>claude-3-opus-20240229>gpt-4-turbo
看得出来,本土大模型在中文任务上对国外大模型有比较大的优势(不过新发布的GPT-4o真的很强),而很多不同数据集测出的所谓“最强中文大模型”其实参考意义不大,看看就好。还是需要根据不同的任务选择最合适的模型。



喜欢这篇文章的人也看了






评论
匿名评论隐私政策





